You are viewing documentation for Kubernetes version: v1.30
Kubernetes v1.30 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date information, see the latest version.
Kyma - extend and build on Kubernetes with ease
According to this recently completed CNCF Survey, the adoption rate of Cloud Native technologies in production is growing rapidly. Kubernetes is at the heart of this technological revolution. Naturally, the growth of cloud native technologies has been accompanied by the growth of the ecosystem that surrounds it. Of course, the complexity of cloud native technologies have increased as well. Just google for the phrase “Kubernetes is hard”, and you’ll get plenty of articles that explain this complexity problem. The best thing about the CNCF community is that problems like this can be solved by smart people building new tools to enable Kubernetes users: Projects like Knative and its Build resource extension, for example, serve to reduce complexity across a range of scenarios. Even though increasing complexity might seem like the most important issue to tackle, it is not the only challenge you face when transitioning to Cloud Native.
Problems to solve
Picking the right technology is hard
Now that you understand Kubernetes, your teams are trained and you’ve started building applications on top, it’s time to face a new layer of challenges. Cloud native doesn’t just mean deploying a platform for developers to build on top of. Developers also need storage, backup, monitoring, logging and a service mesh to enforce policies upon data in transit. Each of these individual systems must be properly configured and deployed, as well as logged, monitored and backed up on its own. The CNCF is here to help. We provide a landscape overview of all cloud-native technologies, but the list is huge and can be overwhelming.
This is where Kyma will make your life easier. Its mission statement is to enable a flexible and easy way of extending applications.
This project is designed to give you the tools you need to be able to write an end-to-end, production-grade cloud native application. Kyma was donated to the open-source community by SAP; a company with great experience in writing production-grade cloud native applications. That’s why we’re so excited to -- announce the first major release of Kyma 1.0!
Deciding on the path from monolith to cloud-native is hard
Try Googling monolith to cloud native or monolith to microservices and you’ll get a list of plenty of talks and papers that tackle this challenge. There are many different paths available for migrating a monolith to the cloud, and our experience has taught us to be quite opinionated in this area. First, let's answer the question of why you’d want to move from monolith to cloud native. The goals driving this move are typically:
- Increased scalability.
- Faster implementation of new features.
- More flexible approach to extensibility.
You do not have to rewrite your monolith to achieve these goals. Why spend all that time rewriting functionality that you already have? Just focus on enabling your monolith to support event-driven architecture.
How does Kyma solve your challenges?
What is Kyma?
Kyma runs on Kubernetes and consists of a number of different components, three of which are:
- Application connector that you can use to connect any application with a Kubernetes cluster and expose its APIs and Events through the Kubernetes Service Catalog.
- Serverless which enables you to easily write extensions for your application. Your function code can be triggered by API calls and also by events coming from external system. You can also securely call back the integrated system from your function.
- Service Catalog is here to expose integrated systems. This integration also enables you to use services from hyperscalers like Azure, AWS or Google Cloud. Kyma allows for easy integration of official service brokers maintained by Microsoft and Google.

You can watch this video for a short overview of Kyma key features that is based on a real demo scenario.
We picked the right technologies for you
You can provide reliable extensibility in a project like Kyma only if it is properly monitored and configured. We decided not to reinvent the wheel. There are many great projects in the CNCF landscape, most with huge communities behind them. We decided to pick the best ones and glue them all together in Kyma. You can see the same architecture diagram that is above but with a focus on the projects we put together to create Kyma:
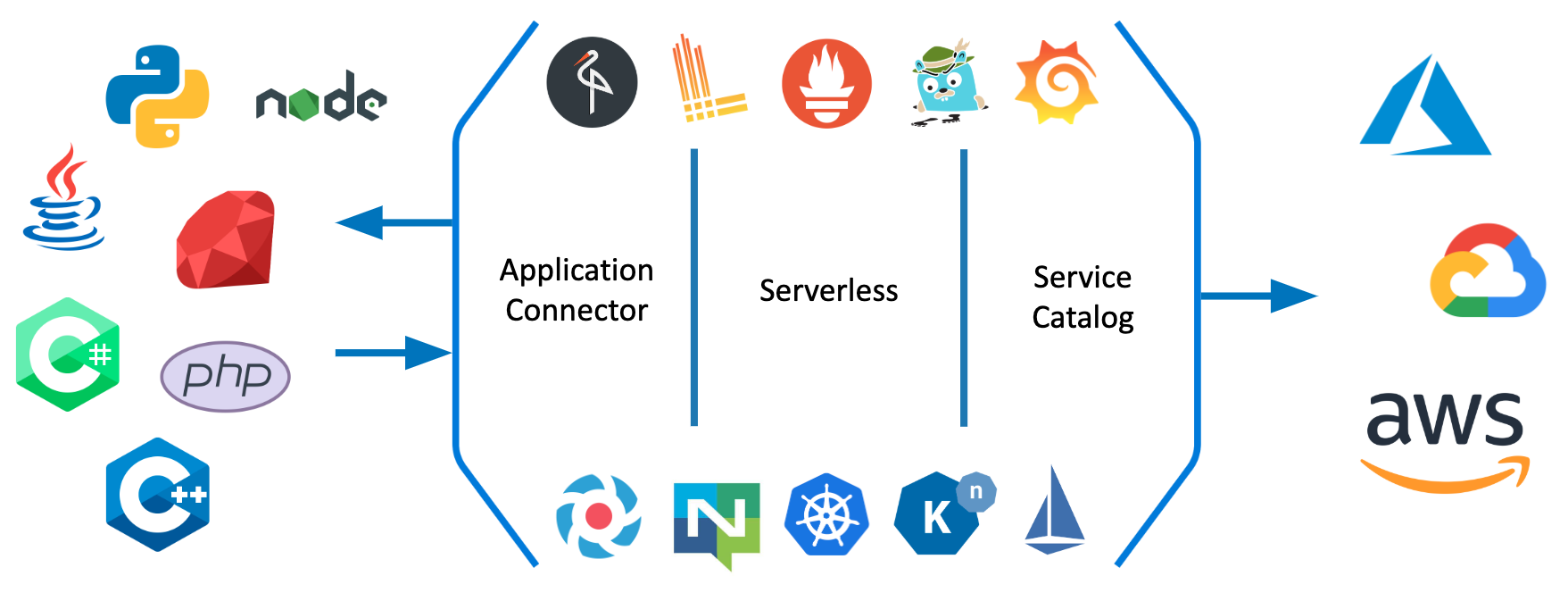
- Monitoring and alerting is based on Prometheus and Grafana
- Logging is based on Loki
- Eventing uses Knative and NATS
- Asset management uses Minio as a storage
- Service Mesh is based on Istio
- Tracing is done with Jaeger
- Authentication is supported by dex
You don't have to integrate these tools: We made sure they all play together well, and are always up to date ( Kyma is already using Istio 1.1). With our custom Installer and Helm charts, we enabled easy installation and easy upgrades to new versions of Kyma.
Do not rewrite your monoliths
Rewriting is hard, costs a fortune, and in most cases is not needed. At the end of the day, what you need is to be able to write and put new features into production quicker. You can do it by connecting your monolith to Kyma using the Application Connector. In short, this component makes sure that:
- You can securely call back the registered monolith without the need to take care of authorization, as the Application Connector handles this.
- Events sent from your monolith get securely to the Kyma Event Bus.
At the moment, your monolith can consume three different types of services: REST (with OpenAPI specification) and OData (with Entity Data Model specification) for synchronous communication, and for asynchronous communication you can register a catalog of events based on AsyncAPI specification. Your events are later delivered internally using NATS Streaming channel with Knative eventing.
Once your monolith's services are connected, you can provision them in selected Namespaces thanks to the previously mentioned Service Catalog integration. You, as a developer, can go to the catalog and see a list of all the services you can consume. There are services from your monolith, and services from other 3rd party providers thanks to registered Service Brokers, like Azure's OSBA. It is the one single place with everything you need. If you want to stand up a new application, everything you need is already available in Kyma.
Finally some code
Check out some code I had to write to integrate a monolith with Azure services. I wanted to understand the sentiments shared by customers under the product's review section. On every event with a review comment, I wanted to use machine learning to call a sentiments analysis service, and in the case of a negative comment, I wanted to store it in a database for later review. This is the code of a function created thanks to our Serverless component. Pay attention to my code comments:
You can watch this short video for a full demo of sentiment analysis function.
/* It is a function powered by NodeJS runtime so I have to import some necessary dependencies. I choosed Azure's CosmoDB that is a Mongo-like database, so I could use a MongoClient */
const axios = require("axios");
const MongoClient = require('mongodb').MongoClient;
module.exports = { main: async function (event, context) {
/* My function was triggered because it was subscribed to customer review event. I have access to the payload of the event. */
let negative = await isNegative(event.data.comment)
if (negative) {
console.log("Customer sentiment is negative:", event.data)
await mongoInsert(event.data)
} else {
console.log("This positive comment was not saved:", event.data)
}
}}
/* Like in case of isNegative function, I focus of usage of the MongoClient API. The necessary information about the database location and an authorization needed to call it is injected into my function and I just need to pick a proper environment variable. */
async function mongoInsert(data) {
try {
client = await MongoClient.connect(process.env.connectionString, { useNewUrlParser: true });
db = client.db('mycommerce');
const collection = db.collection('comments');
return await collection.insertOne(data);
} finally {
client.close();
}
}
/* This function calls Azure's Text Analytics service to get information about the sentiment. Notice process.env.textAnalyticsEndpoint and process.env.textAnalyticsKey part. When I wrote this function I didn't have to go to Azure's console to get these details. I had these variables automatically injected into my function thanks to our integration with Service Catalog and our Service Binding Usage controller that pairs the binding with a function. */
async function isNegative(comment) {
let response = await axios.post(`${process.env.textAnalyticsEndpoint}/sentiment`,
{ documents: [{ id: '1', text: comment }] }, {headers:{ 'Ocp-Apim-Subscription-Key': process.env.textAnalyticsKey }})
return response.data.documents[0].score < 0.5
}
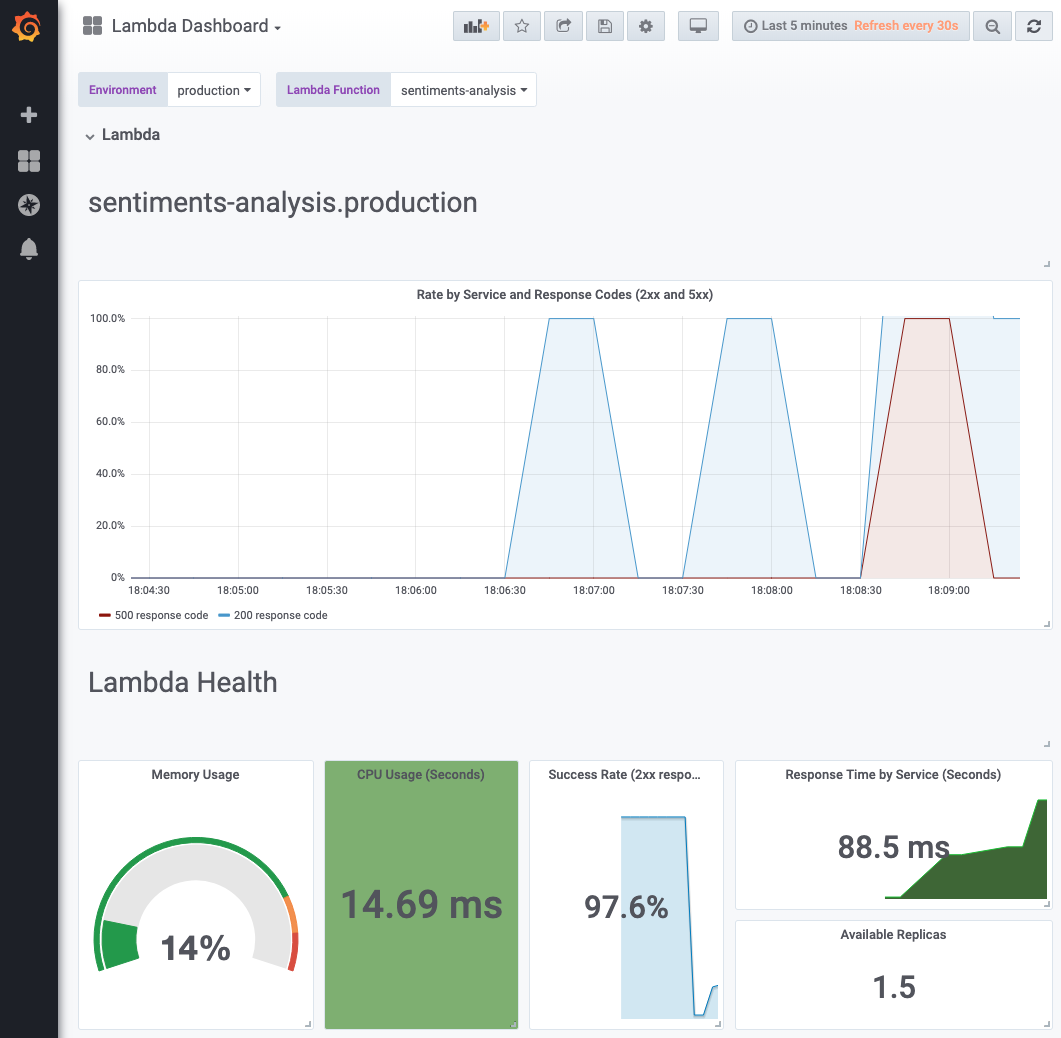
Thanks to Kyma, I don't have to worry about the infrastructure around my function. As I mentioned, I have all the tools needed in Kyma, and they are integrated together. I can quickly get access to my logs through Loki, and I can quickly get access to a preconfigured Grafana dashboard to see the metrics of my Lambda delivered thanks to Prometheus and Istio.
Such an approach gives you a lot of flexibility in adding new functionality. It also gives you time to rethink the need to rewrite old functions.
Contribute and give feedback
Kyma is an open source project, and we would love help it grow. The way that happens is with your help. After reading this post, you already know that we don't want to reinvent the wheel. We stay true to this approach in our work model, which enables community contributors. We work in Special Interest Groups and have publicly recorded meeting that you can join any time, so we have a setup similar to what you know from Kubernetes itself. Feel free to share also your feedback with us, through Twitter or Slack.