You are viewing documentation for Kubernetes version: v1.30
Kubernetes v1.30 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date information, see the latest version.
Scaling neural network image classification using Kubernetes with TensorFlow Serving
In 2011, Google developed an internal deep learning infrastructure called DistBelief, which allowed Googlers to build ever larger neural networks and scale training to thousands of cores. Late last year, Google introduced TensorFlow, its second-generation machine learning system. TensorFlow is general, flexible, portable, easy-to-use and, most importantly, developed with the open source community.

The process of introducing machine learning into your product involves creating and training a model on your dataset, and then pushing the model to production to serve requests. In this blog post, we’ll show you how you can use Kubernetes with TensorFlow Serving, a high performance, open source serving system for machine learning models, to meet the scaling demands of your application.
Let’s use image classification as an example. Suppose your application needs to be able to correctly identify an image across a set of categories. For example, given the cute puppy image below, your system should classify it as a retriever.
|  |
| Image via Wikipedia |
|
| Image via Wikipedia |
{kind=link}
You can implement image classification with TensorFlow using the Inception-v3 model trained on the data from the ImageNet dataset. This dataset contains images and their labels, which allows the TensorFlow learner to train a model that can be used for by your application in production.
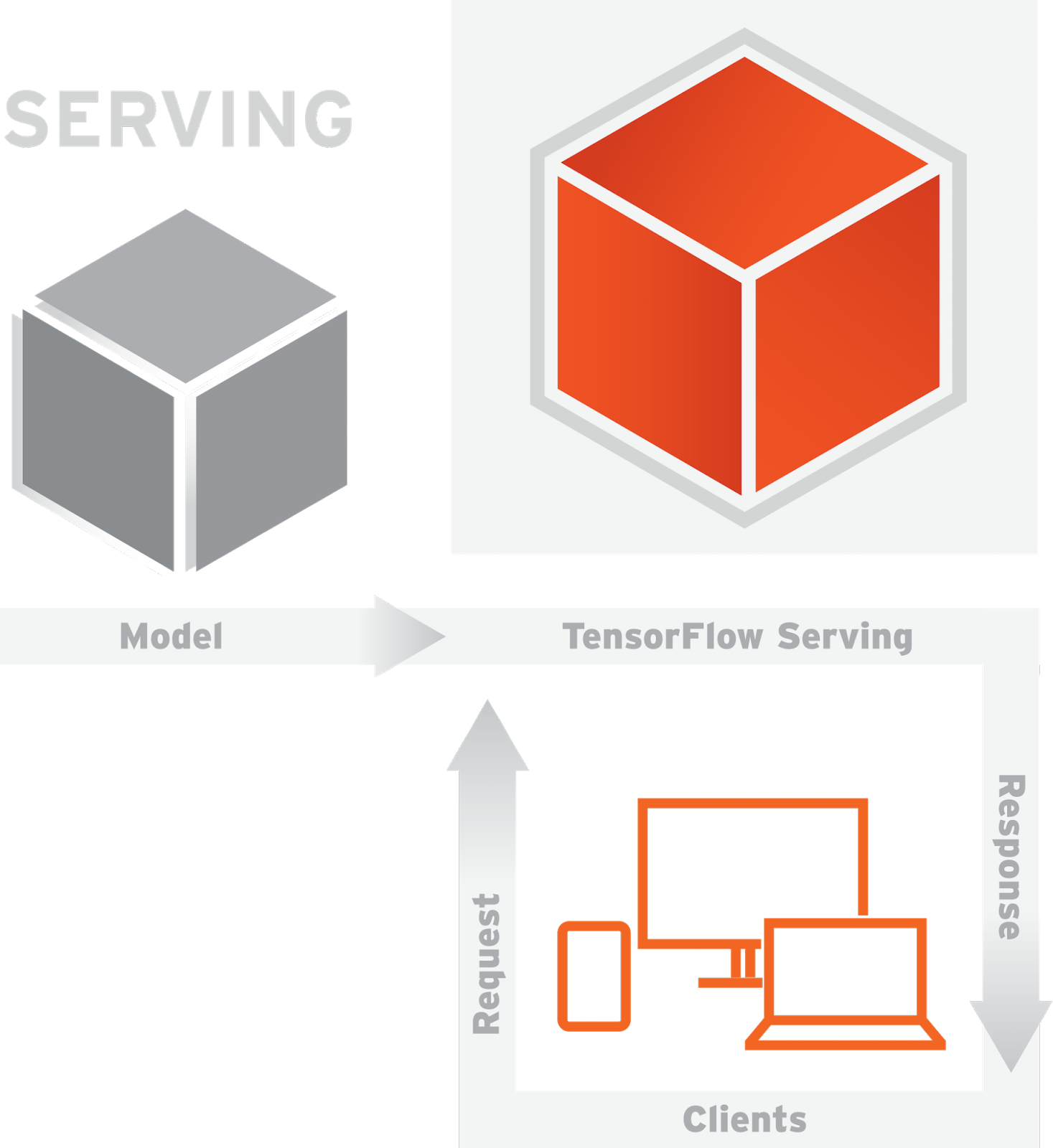
 Once the model is trained and exported, TensorFlow Serving uses the model to perform inference — predictions based on new data presented by its clients. In our example, clients submit image classification requests over gRPC, a high performance, open source RPC framework from Google.
Once the model is trained and exported, TensorFlow Serving uses the model to perform inference — predictions based on new data presented by its clients. In our example, clients submit image classification requests over gRPC, a high performance, open source RPC framework from Google.
Inference can be very resource intensive. Our server executes the following TensorFlow graph to process every classification request it receives. The Inception-v3 model has over 27 million parameters and runs 5.7 billion floating point operations per inference.
|  |
| Schematic diagram of Inception-v3 |
|
| Schematic diagram of Inception-v3 |
Fortunately, this is where Kubernetes can help us. Kubernetes distributes inference request processing across a cluster using its External Load Balancer. Each pod in the cluster contains a TensorFlow Serving Docker image with the TensorFlow Serving-based gRPC server and a trained Inception-v3 model. The model is represented as a set of files describing the shape of the TensorFlow graph, model weights, assets, and so on. Since everything is neatly packaged together, we can dynamically scale the number of replicated pods using the Kubernetes Replication Controller to keep up with the service demands.
To help you try this out yourself, we’ve written a step-by-step tutorial, which shows you how to create the TensorFlow Serving Docker container to serve the Inception-v3 image classification model, configure a Kubernetes cluster and run classification requests against it. We hope this will make it easier for you to integrate machine learning into your own applications and scale it with Kubernetes! To learn more about TensorFlow Serving, check out tensorflow.github.io/serving.